
여러 개의 서버 인스턴스를 연결하는 방법
하나의 서비스가 있다고 가정해보자.
만약 이 서비스를 여러 개의 서버 인스턴스에서 실행하려면 어떻게 해야할까?
일종의 로드 밸런서가 있다면 어떻게 동작할지 알아보자.
PC가 1대만 있는 경우
PC가 만약 1대만 있다면 어떻게 하면 될까?
이 때는 사용되는 포트를 분리하면 된다.
일반적으로 사용되는 포트는 8080번 포트이다.
이 때 3개의 서버 인스턴스를 사용하고 싶다면,
보통 8080번 포트를 제외한 2개의 추가 포트를 정의한다.
예시를 들면 아래와 같은 형태가 된다.
- 기본
http://localhost:8080
- 추가 서버 - 1
http://localhost:8081
- 추가 서버 - 2
http://localhost:8082
PC가 여러 대 있는 경우
PC가 여러 대 있다면 어떻게 하면 될까?
이 때는 각 서버의 주소를 연결하면 된다.
예시를 들면 아래와 같은 형태가 된다.
- 기본
http://주소1:8080
- 추가 서버 - 1
http://주소2:8080
- 추가 서버 - 2
http://주소3:8080
각 서비스는 어떻게 연결할까?
PC를 1대를 쓰든 여러 대를 쓰든 일단 주소를 정의하는 방법은 알게 됬다.
그런데 결국 상황에 맞게 각각의 인스턴스에 맞게 트래픽을 넘기려면
어딘가에 이 연결 정보를 저장해야 한다.
스프링 진영에서는 이러한 연결 정보를 관리하는 기술을 제공하는데
이 기술을 서비스 디스커버리(Service Discovery)라고 부른다.
이 서비스 디스커버리에는 각 서비스에 대한 정보가
key-value 형태로 저장된다.
서비스 디스커버리의 동작 원리
구조를 이해하기 위해 아래와 같은 아키텍처가 있다고 가정해보자.
flowchart LR
A["클라이언트"] --- B["로드 밸런서<br/>or<br/>API 게이트웨이"]
B --- C["서비스 디스커버리"]
C --- D1["서비스 인스턴스 1"]
C --- D2["서비스 인스턴스 2"]
C --- D3["서비스 인스턴스 3"]
이 때 클라이언트가 서비스 인스턴스 1을 호출하려고 하면 아래와 같이 동작한다.
flowchart LR
A["클라이언트"] -."①".-> B["로드 밸런서<br/>or<br/>API 게이트웨이"]
B -."②".-> C["서비스 디스커버리"]
C -."③".-> B
C --- D1["서비스 인스턴스 1"]
C --- D2["서비스 인스턴스 2"]
C --- D3["서비스 인스턴스 3"]
B -."④".-> D1
D1 -."⑤".-> A
- 클라이언트가 API 게이트웨이에 요청을 전달한다.
- API 게이트웨이 대신에 로드 밸런서였어도 대략적인 방법은 동일하다고 보면 된다.
- API 게이트웨이가 서비스 디스커버리에서 서비스 인스턴스 목록을 조회한다.
- API 게이트웨이가 내부 로드 밸런서를 사용해서 특정 인스턴스를 선택한다.
- API 게이트웨이가 선택한 서비스 인스턴스로 직접 요청을 전달한다.
- 서비스에서 클라이언트의 요청을 처리하고 그 결과를 클라이언트에 반환한다.
Spring Cloud Netflix Eureka
각각의 마이크로서비스에 대한 정보는 서비스 디스커버리에 등록해야 한다.
그런데 이 서비스 디스커버리는 데이터베이스가 아니라 서버다.
등록해야 된다고 해서 해당 기술을 처음 접하면 혹시 데이터베이스인가? 싶을 수도 있는데,
실제로는 전용 서버에 각 마이크로서비스에 대한 정보를 직접 등록하는 것이다.
서비스 디스커버리는 Eureka 서버라고 부른다.
정확히는 Spring Cloud Netflix Eureka인데,
이름을 보면 알 수 있듯이 해당 기술은 OTT 기업인 넷플릭스에서 제작된 기술이다.
넷플릭스에서 스프링 진영에 기술을 제공해서 발전한 것이 현재의 Spring Cloud Netflix Eureka다.
보통 요약해서 유레카 또는 유레카 서버라고 부른다.
유레카 서버 만들기
서비스 디스커버리를 생성하기 위해서는 유레카 서버를 만들어야 한다.
build.gradle
유레카 서버를 만들기 위해서는 build.gradle에 아래와 같이 추가해주면 된다.
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'유레카 서버로 등록하기
단순히 의존성만 추가해줬다고 유레카 서버가 되는 것은 아니다.
해당 애플리케이션을 유레카 서버로 등록시켜줘야 한다.
스프링 부트 프로젝트라면 @SpringBootApplication 애노테이션이 있는
해당 애플리케이션의 메인 클래스가 있을 것이다.
해당 클래스로 이동해서 @EnableEurekaServer 애노테이션을 추가해주자.
그러면 이제 해당 애플리케이션은 유레카 서버가 된다.
설정 파일 변경하기
유레카 라이브러리가 포함된 채 스프링 부트가 기동이 되면
기본적으로 유레카 클라이언트로 역할로서
어딘가에 등록하는 작업을 시도하게 된다.
그런데 유레카 서버는 서비스 디스커버리를 통해 인스턴스 정보를 저장하는 역할이다.
그래서 유레카 서버에서 자기 자신을 서비스 인스턴스로 등록하려고 한다.
유레카 서버는 정말 서버의 역할만 하면 되니, 이러한 의미없는 작업은 막아둬야 한다.
설정 파일에서 아래의 2가지 속성을 false로 지정하자.
eureka.client.register-with-eurekaeureka.client.fetch-registry
만약 application.yaml이라면 아래와 같이 될 것이다.
eureka:
client:
register-with-eureka: false
fetch-registry: false서버 실행해보기
이제 유레카 서버를 실행해서 웹 브라우저로 메인에 접속해보면
아래와 같은 대시보드가 나온다.
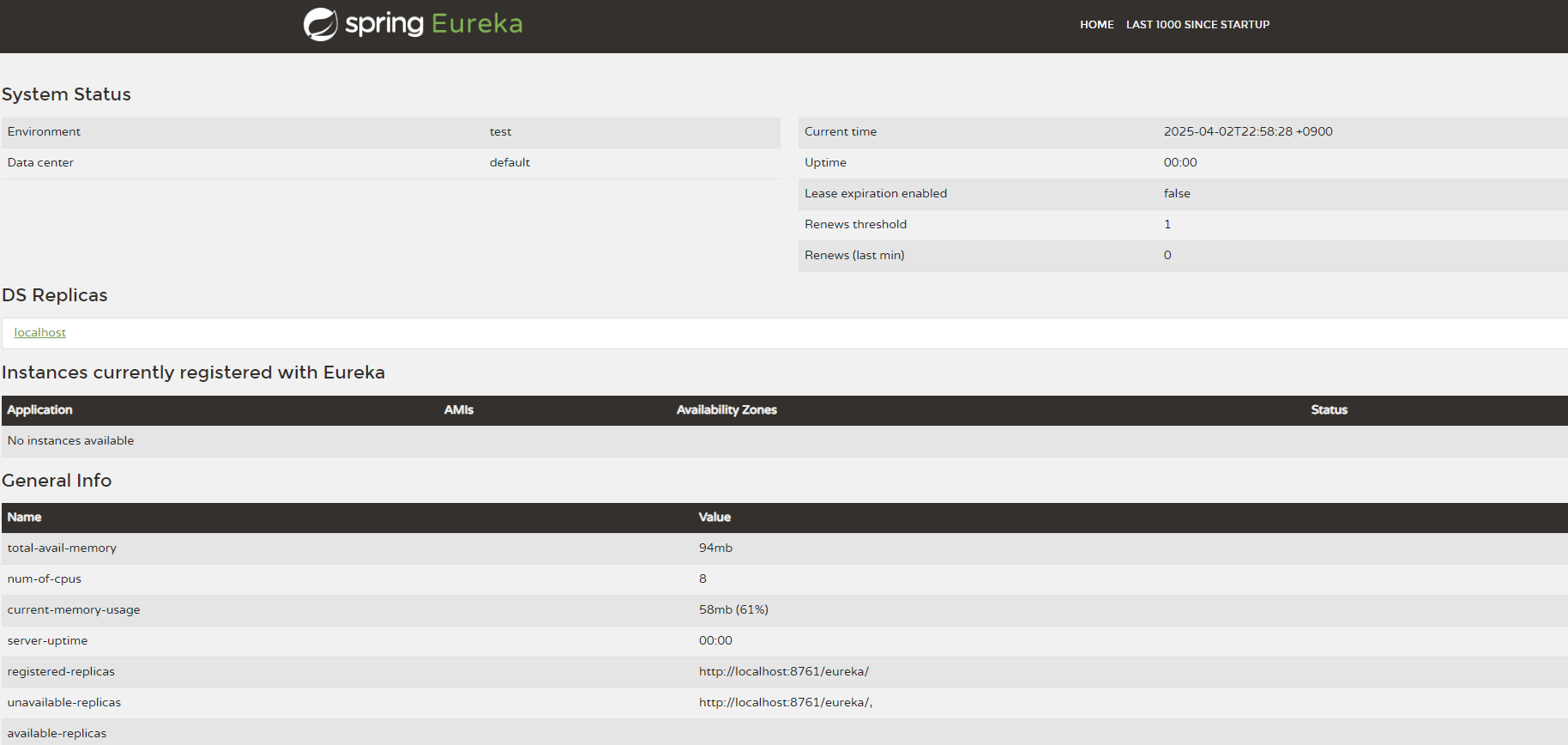
해당 대시보드에서는 서버가 언제 기동이 됬는지,
해당 유레카 서버에 어떤 인스턴스들이 등록되어 있는지에 대한 정보가 노출된다.
서비스 인스턴스 만들기
방금 만든 것은 인스턴스에 대한 정보를 등록하는 유레카 서버였다.
그렇다면 이번에는 유레카 서버에 등록할 인스턴스를 만들어 보자.
이러한 각 인스턴스는 유레카 디스커버리 클라이언트, 줄여서 클라이언트라고 부른다.
build.gradle
유레카 서비스로 만들기 위해서는 build.gradle에 아래와 같이 의존성을 추가해주면 된다.
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'다만 JAVA 17 버전 이상 사용 시 JVM 호환이 안 되서 문제가 생길 수 있다.
build.gradle에 아래의 내용을 추가해주자.
ext {
set('springCloudVersion', "2024.0.1")
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}클라이언트로 등록하기
유레카 서버때와 마찬가지로 의존성만 추가했다고 클라이언트가 되는 것은 아니다.
해당 애플리케이션을 클라이언트로 등록시켜줘야 한다.
@SpringBootApplication 애노테이션이 있는 메인 클래스로 이동해서,
@EnableDiscoveryClient 애노테이션을 추가해주자.
그러면 이제 해당 애플리케이션은 클라이언트가 된다.
설정 파일 변경하기
클라이언트로써 동작하려면 아래의 설정 값을 true로 주면 된다.
기본 값이 true라서 별도로 정의하지 않아도 되긴 하다.
eureka:
client:
register-with-eureka: true
fetch-registry: trueeureka.client.register-with-eureka- 유레카의 레지스트리에 등록할 것인지에 대한 여부
eureka.client.fetch-registry- 유레카 서버로부터 서비스 인스턴스들의 정보를 주기적으로 가져올 것인지에 대한 여부
- true일 경우 갱신된 정보를 받는다.
하지만 위처럼만 설정하면 등록하겠다고만 했지
어디에 등록하겠다고는 정보가 없다.
아래와 같이 유레카 서버에 대한 정보를 명시하자.
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:8761/eurekaeureka.client.service-url.defaultZone에는 유레카 서버의 주소를 명시한다.
정확히는 유레카 서버의 어느 엔드 포인트에
해당 마이크로서비스에 대한 정보를 등록할 지를 명시하는 것이다.
서버 실행해보기
이제 직접 실행해서 확인해보자.
인스턴스를 등록하려면 유레카 서버와 유레카 클라이언트가 모두 실행되어 있어야 한다.
유레카 서버의 대시보드를 새로 고침해보면 아까 등록했던 클라이언트에 대한 정보가 노출되는 것을 확인할 수 있다. 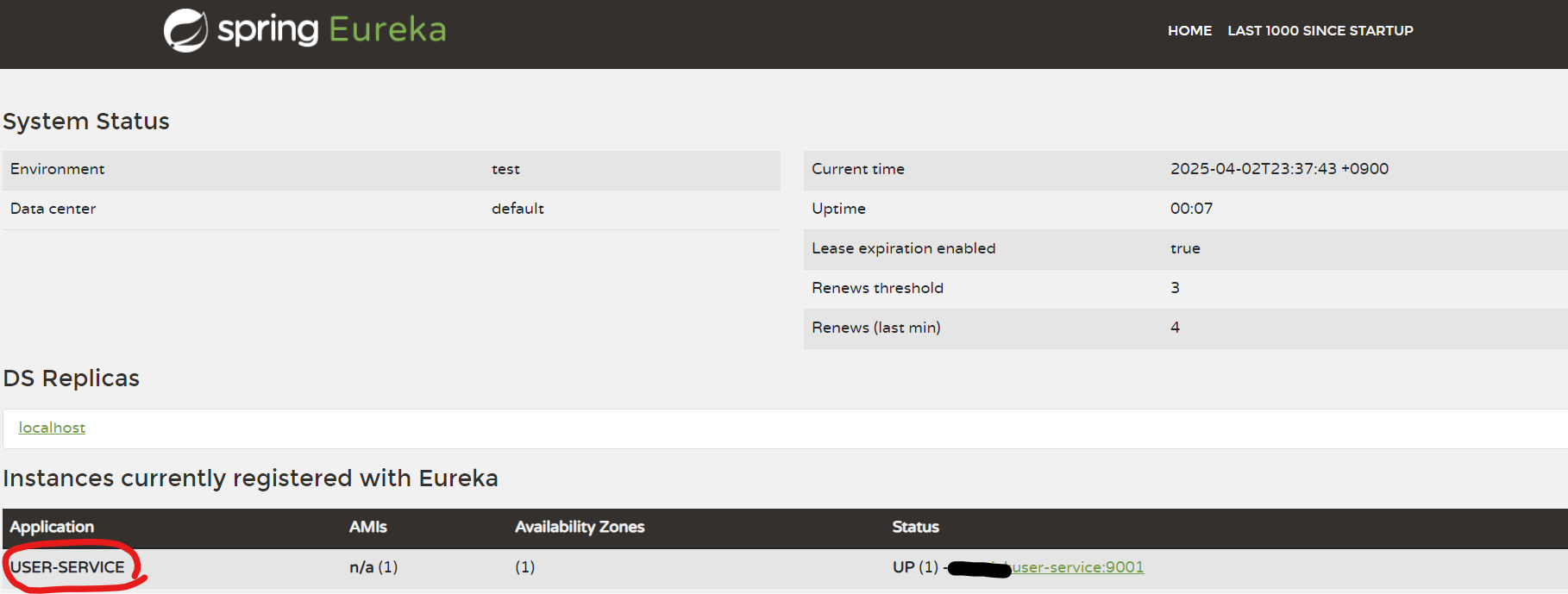
해당 인스턴스명은 spring.application.name 속성에 명시된 애플리케이션의 이름을 사용한다.
실제로 해당 값을 바꿔보면 대시보드에서 노출되는 이름이 달라진다.
참고로 애플리케이션의 이름을 바꿔서 서버를 재실행한 다음에 대시보드를 다시 들어가면
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.라는
문구가 나올텐데 해당 문구는 기존에 서비스 디스커버리에 등록되어 있던 정보랑 달라져서
유레카 서버가 대시보드에 노출시키는 문구다.
인스턴스가 다시 정상적으로 실행된다면 시간이 지나면 해당 문구는 사라진다.
클라이언트 확장하기
만약 운영 환경에서 해당 서비스의 이용 빈도가 높아서
해당 서비스의 인스턴스를 늘린다고 가정해보자.
IDE에서 확인해보기
인텔리제이를 사용한다는 가정하에 진행해보자.
실행 구성을 편집하는 메뉴에 들어가서
기존 구성을 복사해서 VM 옵션을 추가해주자.
그런 다음에 VM 옵션에 -Dserver.port=포트_번호를 입력하고 저장하면 된다.
이 때의 포트 번호는 해당 프로젝트에서 사용 중인 포트말고 다른 포트의 번호를 명시한다.
이제 추가된 실행 구성을 실제로 실행해보고 유레카 대시보드를 새로고침해보자.
그러면 아래와 같이 하나의 이름으로 2개의 인스턴스가 등록된 것을 확인할 수 있다. 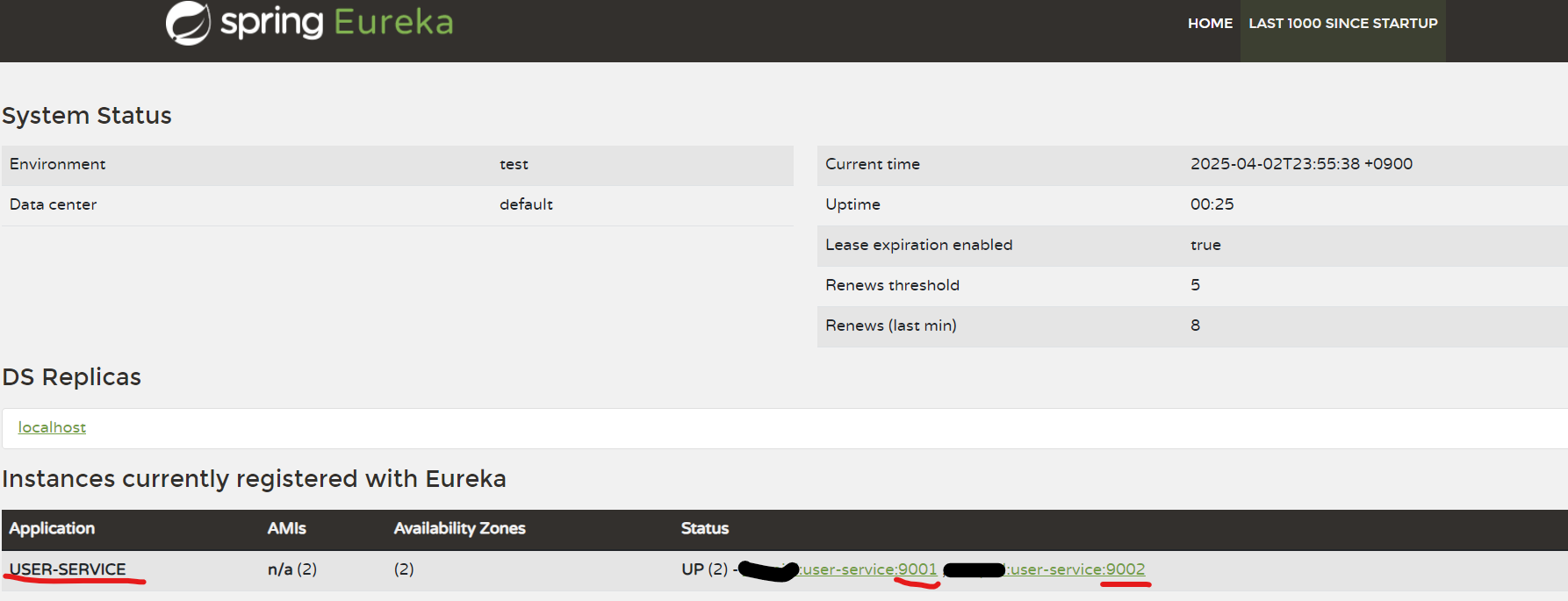
터미널에서 확인해보기
CMD나 IDE의 터미널을 통해
해당 프로젝트의 경로로 이동한 다음에
명령어를 실행해서 서버를 실행할 수도 있다.
우선 ./gradlew build 명령어를 실행해서 .jar 파일로 빌드한다.
그 다음에 java -jar 빌드한_파일명 --server.port=9002처럼 실행하면 된다.
java -jar .\build\libs\user-service-0.0.1-SNAPSHOT.jar --server.port=9002같은 형태다.
아니면 build.gradle에 가서 아래의 코드를 추가해주자.
bootRun {
if (project.hasProperty('args')) {
args project.args.split(',')
}
}그런 다음에 ./gradlew bootRun -Pargs="--server.port=9003"처럼 실행하면
동일하게 포트 번호를 넘기면서 애플리케이션을 실행할 수 있다.
랜덤 포트 사용하기
포트를 일일이 지정하다면 충돌이 발생할 가능성이 있다.
그래서 스프링에서는 랜덤 포트라는 기능을 제공하는데,
설정 파일에서 server.port의 값을 0으로 지정하게 되면
같은 애플리케이션이 실행되더라도 실제 인스턴스가 다르기만 하면
중복되지 않는 포트 번호로 실행하게 된다.
다만 유레카의 대시보드를 다시 확인해보면 알 수 있는데,
별도의 지정이 없으면 Status에는 애플리케이션명:포트번호처럼 명시가 되어 있다.
그런데 실제로는 랜덤 포트로 실행되었지만 유레카 서버 입장에서는
애플리케이션의 설정을 읽어 들였을 때 동일한 포트를 사용하기 때문에
몇 개의 인스턴스를 실행하던지 애플리케이션명:0처럼 보이게 된다. 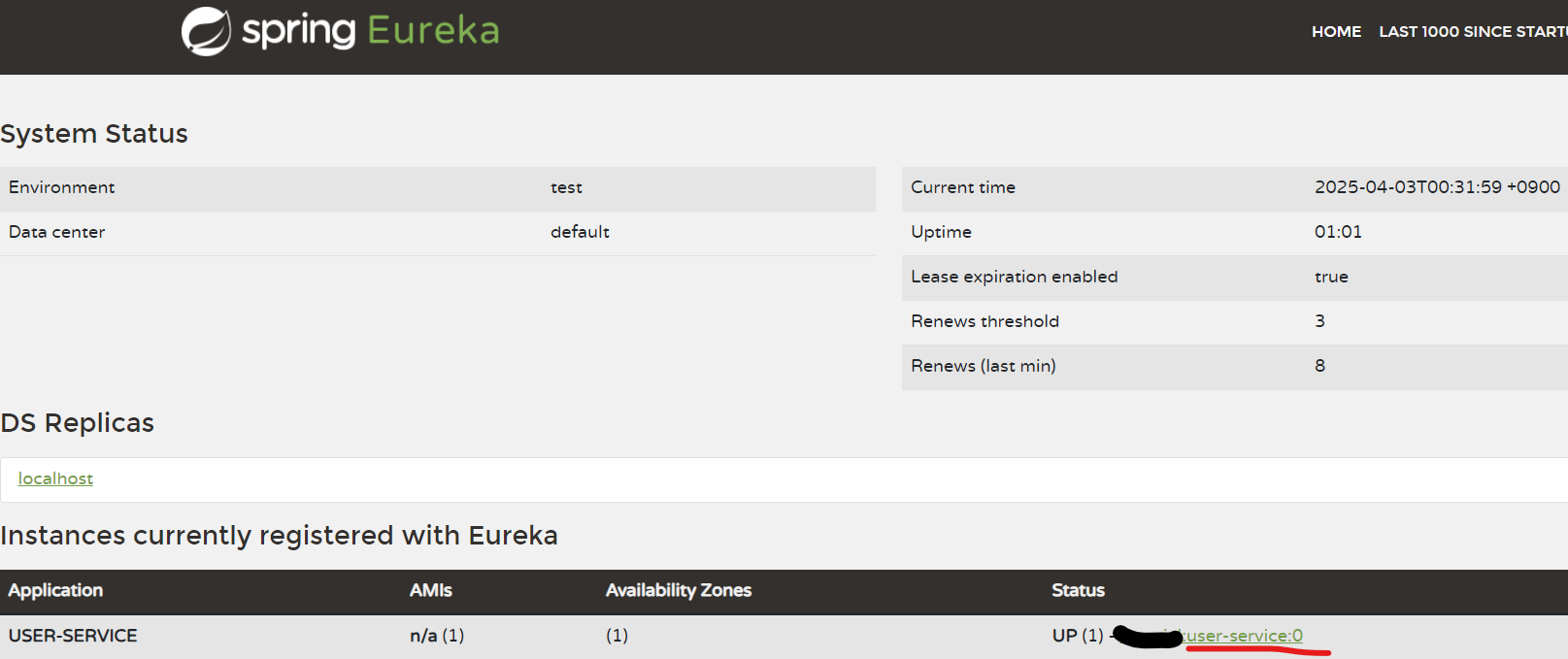
실제 실행 중인 인스턴스 목록을 확인하기 위해서는
설정 파일에서 별도의 설정을 추가해줘야 한다.
설정 파일로 이동해서 eureka.instance.instance-id 속성을 추가해주자.
해당 속성에는 각 인스턴스의 고유한 이름을 명시하면 된다. 그런데 단순히 텍스트로 적게 되면 모든 인스턴스가 같은 이름이기 때문에
랜덤한 이름이 들어가게 하기 위해
${spring.cloud.client.hostname}:${spring.application.instance.id:${random.value}}처럼 명시하자. 그러면 각 인스턴스마다 호스트명:랜덤값와 고유한 이름이 부여된다.
여태까지 작업한 것을 합치면 아래와 같다.
eureka:
instance:
instance-id: ${spring.cloud.client.hostname}:${spring.application.instance.id:${random.value}}
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:8761/eureka유레카 대시보드를 확인해보면 실제로 랜덤한 이름이 부여되는 것을 확인할 수 있다. 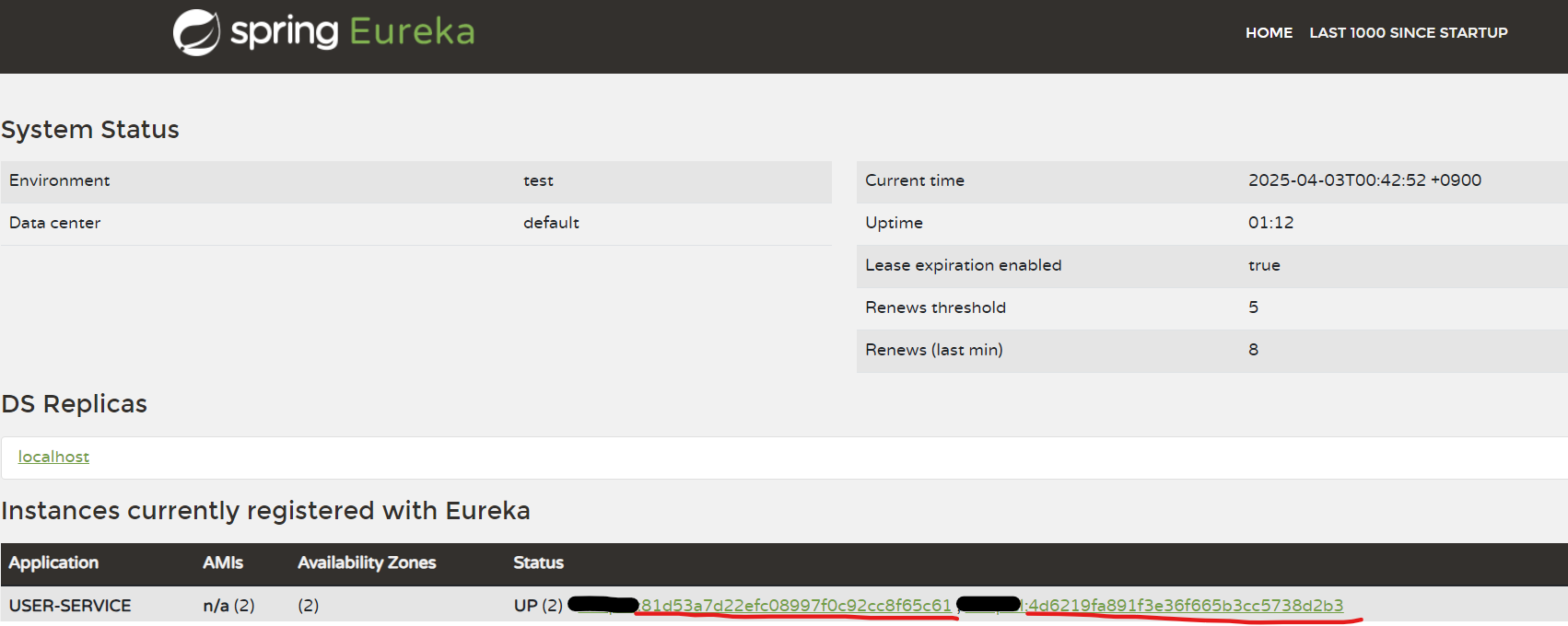
참고로 대시보드에서 각 인스턴스에 대한 링크에 마우스를 올려보거나,
또는 직접 링크를 타고 들어가는 것을 통해 랜덤하게 부여된 포트 번호를 확인할 수 있다.