마이크로서비스 통신 시 연쇄 오류
만약에 회원 정보를 조회하는 API를 호출했을 때
아래와 같은 구조 마이크로서비스가 이어져 있다고 가정해보자.
flowchart LR
A[클라이언트] --> B[게이트웨이]
B --> C[사용자 서비스]
C --> D[주문 서비스]
D --> E[상품 서비스]
사용자 정보를 조회하면
해당 사용자가 등록한 주문 목록이 있고,
주문 목록에는 각 상품에 대한 정보가 있는 것이다.
그런데 이 때 주문 서비스의 인스턴스가 내려가있다면 어떻게 될까?
사용자 서비스에서 사용자의 정보를 조회했어도
주문 서비스를 호출하는 것 자체를 실패한다면
사용자 서비스 입장에서는 주문 정보를 조회하지 못 했으니 500 에러를 반환할 것이다.
최종적으로 아래와 같은 결과를 반환할 것이다.
{
"timestamp": "2025-04-18T11:41:22.041+00:00",
"status": 500,
"error": "Internal Server Error",
"path": "/users/538b2f49-622d-49b3-9753-1e3aaa409dd9"
}물론 예외 처리를 잘 했다면 아래처럼 오류는 안 나게 만들 수 있을 것이다.
{
"email": "test@gmail.com",
"name": "Go Gil Dong",
"userId": "f87713c9-7509-4fef-9f93-ac77a029779d",
"orders": []
}하지만 문제점은 결국 API를 호출할 때마다
장애가 발생하는 서비스를 호출한 다는 것이다.
그러면 장애가 발생하는 서비스 뿐만 아니라
그 이후에 이어질 다른 서비스도 연쇄적으로 오류가 발생한다.
이러한 문제점을 해결하려면 어떻게 해야 할까?
Circuit Breaker (회로 차단기)
정의
- 장애 전파를 방지하고 시스템을 안정적으로 유지하기 위한 보호 장치
- 지속적인 실패가 발생하는 경우, 외부 시스템 호출을 차단하여 전체 시스템의 장애 확산을 방지하는 패턴
- 장애가 감지되면 요청 흐름을 끊는다.
특징
- 상태 전이
- Closed → Open → Half-Open 상태로 변화하며 요청 흐름을 제어한다.
- 실패 기준
- 설정된 실패 비율이나 횟수 초과 시 회로를 다시 열도록 설정할 수 있다.
- 자동 복구
- 일정 시간 후 일부 요청을 시도(Half-Open), 성공 시 다시 Closed로 복귀
- 호출 차단
- 회로가 Open되면 요청을 바로 실패 처리
- Fallback 사용 가능
- 서비스 보호
- 장애 서비스로의 호출을 막아 전체 서비스의 안정성을 확보한다.
장점
- 장애 전파 방지
- 문제가 있는 서비스로의 과도한 재시도나 대기 시간을 줄여 전체 시스템을 보호한다.
- 자원 낭비 방지
- 실패가 예상되는 호출을 미리 차단한다.
- 스레드나 커넥션 같은 자원을 아낄 수 있다.
- 빠른 대응 및 복구
- 장애 시 빠르게 회로를 열고, 일정 시간 후 자동으로 테스트하며 정상 여부를 확인한다.
- Fallback 처리 용이
- 실패 시 대체 처리 로직(Fallback)을 쉽게 구현할 수 있습니다.
- 예시 : “잠시 후 다시 시도해 주세요”라는 메시지 반환
단점
- 설정 민감도
- Failure rate, Wait duration, Ring buffer size 등 설정이 복잡하다.
- 설정이 복잡하다 보니 잘못하면 오히려 정상 요청도 차단될 수 있다.
- 상태 전이 이해 필요
- Open, Closed, Half-Open 상태를 제대로 이해하지 못하면 예기치 못한 동작이 발생할 수 있다.
- 부담스라운 초기 설정
- 실패 기준, 시도 횟수, 대기 시간 등의 세밀한 튜닝이 필요하다.
- 사용자 경험 악화 가능성
- 회로가 열려 있는 동안 사용자 요청이 바로 실패 처리되기 때문에 사용자 경험이 떨어질 수 있다.
Resilience4J
정의
- Java용 경량 장애 회복 라이브러리
- Netflix의 Hystrix가 더 이상 유지보수되지 않으면서 최근 사용하게 되었다.
주요 기능
- CircuitBreaker (회로 차단기)
- Retry (재시도)
- RateLimiter (요청 속도 제한)
- TimeLimiter (응답 시간 제한)
- Bulkhead (스레드 격리)
특징
- Java 8+
- 람다 기반 함수형 스타일로 사용 가능 (간결하고 직관적)
- 모듈화 구조
- 필요한 기능만 의존성 추가해서 경량화 가능
- Spring Boot 통합
- Spring Boot + Spring Cloud 환경에서 사용하기 쉬움
- 설정 방식
- application.yml 설정 or Java 코드로 직접 구성 모두 가능
- 모니터링
- Micrometer, Prometheus와 연동해 상태/성능 모니터링 가능
장점
- 경량화 & 빠름
- Hystrix보다 훨씬 가볍고 빠르다.
- Netty나 RxJava 등 불필요한 의존성이 없다.
- 모듈화된 설계
- CircuitBreaker만 쓰거나, Retry만 쓰는 식으로 필요한 기능만 가져다 쓸 수 있다.
- 손쉬운 Spring 통합
- Spring Boot Starter를 통해 어노테이션 기반 설정도 가능하다.
- 예시
@CircuitBreaker@Retry@RateLimiter
- 실시간 모니터링
- Micrometer와 연동하여 각 기능의 동작 상태를 실시간으로 시각화할 수 있다.
- 예시 : Grafana
- 비동기 & 리액티브 지원
- CompletableFuture, Reactor 등과 함께 사용할 수 있다.
단점
- 러닝 커브 존재
- 처음 접하는 사람에게는 기능이 많고 설정 항목이 많아 복잡하게 느껴질 수 있다.
- 세밀한 튜닝 필요
- 단순 사용은 쉬우나 실무에서는 실패율, 대기 시간 등 튜닝이 중요하다.
- 잘못 설정하면 회로가 자주 열리거나, 너무 오래 닫혀 있을 수 있다.
- 예외 핸들링이 까다로울 수 있다.
- 특히 비동기/리액티브 환경에서 Fallback 처리, 타임아웃 핸들링이 복잡해질 수 있다.
- Spring 외부 프레임워크에서는 설정이 번거로울 수 있다.
- Spring 환경 외에서는 직접 설정 코드를 더 많이 작성해야 한다.
Circuit Breaker 적용하기
build.gradle
회로 차단기를 적용하기 위해 build.gradle에 의존성을 추가하자.
implementation 'org.springframework.cloud:spring-cloud-starter-circuitbreaker-reactor-resilience4j'서비스 호출 부분 수정
사용자 서비스에서 주문 서비스를 호출하는 부분을 수정해보자.
// 선언부
private final CircuitBreakerFactory circuitBreakerFactory;
// 메소드 부분
CircuitBreaker circuitBreaker = circuitBreakerFactory.create("circuitBreaker");
List<ResponseOrder> orderList = circuitBreaker.run(
() -> orderServiceClient.getOrders(userId).getBody(),
throwable -> new ArrayList<>()
);CircuitBreakerFactory를 통해 회로 차단기를 생성할 수 있다.
CircuitBreaker.run() 메소드를 통해
정상적으로 동작했을 때 반환할 데이터와
오류가 발생했을 때 반환할 데이터를 설정할 수 있다.
이제 아까와 동일하게 주문 서비스의 인스턴스가 내려가 있는 상태로
주문 서비스를 호출하게 되면 주문 목록에 빈 배열이 나오는 것을 확인할 수 있다.
{
"email": "test@gmail.com",
"name": "Go Gil Dong",
"userId": "f87713c9-7509-4fef-9f93-ac77a029779d",
"orders": []
}Circuit Breaker + Resilience4J 적용하기
Resilience4J를 통해 회로 차단기에 대한 상세한 설정을 할 수 있다.
환경설정
Resilience4J를 통해 회로 차단기에 대한 상세한 설정을 하기 위해서는
별도의 환경설정이 필요하다.
기본적인 환경설정은 아래와 같다.
@Configuration
public class Resilience4JConfig {
@Bean
public Customizer<Resilience4JCircuitBreakerFactory> globalCustomConfiguration() {
CircuitBreakerConfig circuitBreakerConfig =
CircuitBreakerConfig.custom()
.failureRateThreshold(4)
.waitDurationInOpenState(Duration.ofMillis(1000))
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.COUNT_BASED)
.slidingWindowSize(2)
.build();
TimeLimiterConfig timeLimiterConfig =
TimeLimiterConfig.custom()
.timeoutDuration(Duration.ofSeconds(4))
.build();
return
factory ->
factory
.configureDefault(
id ->
new Resilience4JConfigBuilder(id)
.timeLimiterConfig(timeLimiterConfig)
.circuitBreakerConfig(circuitBreakerConfig)
.build()
);
}
}위 코드에 나와있지 않는 내용은 공식 문서를 확인해보자.
CircuitBreakerConfig
CircuitBreakerConfig.custom().build()를 통해
회로 차단기에 대한 상세한 설정을 할 수 있다.
- 메소드 설명
failureRateThreshold()- 실패율에 대한 설정
- 백분율로 계산한다.
- 지정한 만큼 실패율이 발생했을 때 회로 차단기를 동작시킨다.
- 기본값 : 50%
waitDurationInOpenState()- 회로 차단기의 유지 시간을 설정한다.
- Duration 클래스를 통해 시간을 설정한다.
- 지정한 시간이 지나고 나면 Half-open 상태가 된다.
- 기본값 : 60초
slidingWindowType()- 회로 차단기가 종료되기 위한 조건을 결정하는 방식
- CircuitBreakerConfig.SlidingWindowType enum을 통해 설정한다.
- COUNT_BASED와 TIME_BASED만 가능하다.
- 기본값 : COUNT_BASED
slidingWindowSize()- 회로 차단기가 종료되기 위한 조건값의 크기
- 기본값 : 100
- 이외에도 다양한 설정이 있다.
TimeLimiterConfig
TimeLimiterConfig.custom().build()를 통해
시간 제한에 대한 상세한 설정을 할 수 있다.
- 메소드 설명
timeoutDuration()- future supplier의 시간 제한을 설정한다.
- Duration 클래스를 통해 시간을 설정한다.
- 기본값 : 1초
cancelRunningFuture()- 타임아웃이후 Future를 취소할지 결정한다.
- true일 경우 취소된다.
- 기본값 : true
마이크로서비스 분산 추적
MSA라는 것은 각각의 서비스가 분산되어 있고,
각 서비스가 필요에 따라 다른 서비스를 호출하는 구조다.
그런데 A => B => C 구조에서 B라는 서비스에서 오류가 발생한다면
A 입장에서는 B가 오류가 났다고 판단할 것이다.
그런데 B가 아니라 C가 오류가 난다면 어떨까?
C가 B에 오류를 반환하면, 다시 B는 A에 오류를 반환할 것이다.
즉, 실질적으로 오류가 난 것은 C인데 A 입장에서는 B에서 오류가 난 것처럼 판단할 수도 있다.
그래서 이처럼 정확하게 어느 위치에서 무슨 일이 있었는지 판단하는 것이 중요하다.
이렇게 분산되어 있는 환경에서 각 서비스의 상태를 파악하는 것이
마이크로서비스 분산 추적이다.
사용 기술
- Zipkin
- 분산 추적 시스템
- 공식문서
- Spring Cloud Sleuth
- 스프링 부트와 Zipkin을 연동시켜 주는 라이브러리
- 스프링 부트 2.X 버전까지 지원
- 깃허브
- Micrometer Tracing
관련 용어
- Trace
- 클라이언트가 서버로 호출한 하나의 호출
- 전체 트렌젝션 시간 추적 시 사용한다.
- Trace Id
- Trace를 구분하는 고유한 Id
- Span
- 서비스 컴포넌트 간의 호출
- 각 서비스별 구간 시간 추적 시 사용한다.
- Span Id
- Span을 구분하는 고유한 Id
Trace 및 Span 원리
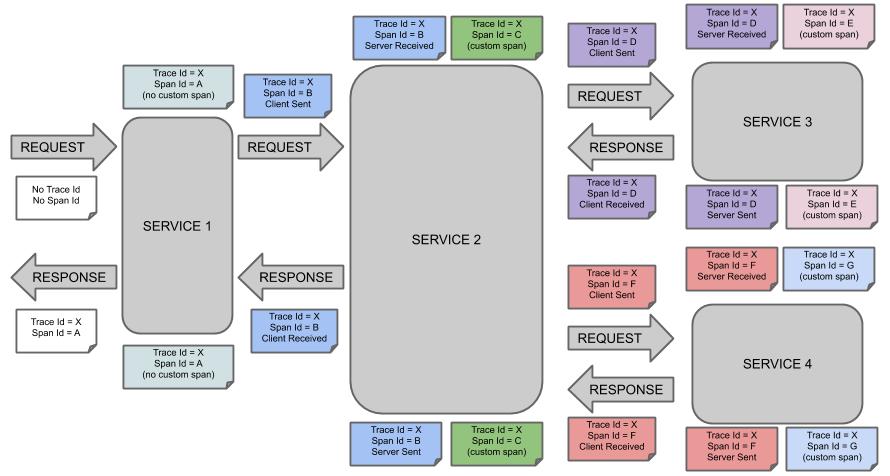
출처 : https://docs.spring.io/spring-cloud-sleuth/docs/current/reference/html/getting-started.html#getting-started
Zipkin
- 분산 시스템에서의 요청 흐름을 시각화하고 추적할 수 있도록 도와주는 오픈소스 APM 도구
- APM (Application Performance Monitoring) : 애플리케이션 성능 모니터링
특징
- 경량 구조
- Java로 작성된 가벼운 추적 서버다.
- 로컬에서도 쉽게 실행할 수 있다.
java -jar 파일명
- 시각화 UI
- 트레이스 정보를 웹에서 확인할 수 있다.
- 예시
- 요청 경로
- 지연 시간
- 서비스 간 관계
- Trace/Span 개념
- Trace ID와 Span ID를 기반으로 요청 흐름을 추적한다.
- 다양한 연동
- Spring Cloud Sleuth, gRPC, Kafka, Elasticsearch 등과 쉽게 연동할 수 있다.
- 저장소 지원
- 기본 In-Memory 외에도 MySQL, Elasticsearch, Cassandra 등을 사용할 수 있다.
- HTTP/JSON 기반
- REST API로 trace data를 수집 및 조회한다.
장점
- 마이크로서비스 디버깅에 탁월
- 서비스 간 호출 경로, 응답 시간, 지연 구간을 한눈에 확인할 수 있다.
- Spring Cloud Sleuth와 자동 연동
- Spring Boot 기반 프로젝트에서는 설정 몇 줄로 바로 연동할 수 있다.
- 빠른 구축
- 설치가 매우 간단하다.
- Docker, JAR, Kubernetes 환경에서도 빠르게 실행할 수 있다.
- 다양한 언어 지원
- Java, Node.js, Python, Go 등 다양한 언어용 클라이언트를 제공한다.
- 오픈소스
- OpenTelemetry 등과 연계도 가능하다.
- 커스터마이징이 쉽다.
단점
- 고도화된 기능이 부족하다.
- APM 도구 치고는 기본적인 추적/시각화 기능만 제공한다.
- 알람, AI 분석, 대시보드 커스터마이징 등은 제한적이다.
- 대용량 트래픽 환경에서는 튜닝이 필요하다.
- 수집량이 많을 경우 Elasticsearch나 Kafka 기반 설정이 필요하다.
- 기본 설정은 메모리 기반이라 제한적이다.
- UI가 비교적 단순한 편이다.
- 시각화가 되는건 사실이다.
- 다만 직관적인 분석 기능은 Grafana나 Jaeger보다 다소 약한 편이다.
- 로그와 연계는 별도로 구현헤야 한다.
- 로그 데이터와 직접 연결되지는 않는다.
- MDC(Logback)와 함께 사용해야 연계적인 분석을 할 수 있다.
설치 및 실행 과정 (Java)
- 설치
curl -sSL https://zipkin.io/quickstart.sh | bash -s- 실행
java -jar zipkin.jar환경변수가 편집되어 있다면 CMD에서 정상적으로 동작하지 않을 수 있다.
그럴 땐 그냥 공식 사이트에서 jar 파일을 바로 다운로드하자.
설치 및 실행 과정 (Docker)
docker run -d -p 9411:9411 openzipkin/zipkin서버 실행 결과
서버가 정상적으로 실행된다면 콘솔에 아래와 같은 화면이 출력된다. 
브라우저에서 http://localhost:9411/zipkin/으로 접속해보면
Zipkin의 분산 추적 상황을 확인할 수 있는 웹 페이지가 나온다.
Spring Cloud Sleuth
정의
- Spring Boot 기반 애플리케이션에 분산 추적 기능을 쉽게 추가할 수 있게 해주는 라이브러리
- 서비스 간 요청 흐름에 Trace ID, Span ID를 자동으로 생성하고 전파하여
전체 시스템의 호출 흐름을 추적할 수 있게 도와준다. - 주로 Zipkin, OpenTelemetry, Brave와 함께 연동해서 사용한다.
특징
- 자동 Trace/Span ID 삽입
- 로그, HTTP 헤더, Kafka 메시지 등 다양한 경로에 자동으로 추적 ID를 삽입한다.
- Spring Boot 친화적
- starter 의존성 추가만으로 쉽게 적용할 수 있다.
spring-cloud-starter-sleuth
- Zipkin 연동
spring-cloud-starter-zipkin의존성 추가 시 자동으로 Zipkin에 데이터를 전송해준다.
- OpenTelemetry 지원
- Sleuth 3.x 이후부터는 OpenTelemetry 기반 확장도 가능하다.
- ThreadLocal 기반
- Trace 정보는 ThreadLocal로 관리된다.
- 비동기 처리 시 주의가 필요하다.
장점
- 자동화된 추적 정보 관리
- Trace ID, Span ID를 수동으로 신경 쓸 필요 없이 자동으로 생성 및 전파해준다.
- 로그 연동(MDC) 용이
- Logback, Log4j2 등 로그에 자동으로
[Trace ID, Span ID]를 삽입해준다. - 디버깅이 쉬워진다.
- Logback, Log4j2 등 로그에 자동으로
- Zipkin, Brave, Kafka 등과 유연한 통합이 가능하다.
- Zipkin 연동 시 별도 설정 없이 트레이스를 자동으로 전송한다.
- 마이크로서비스 호출 추적
- 요청 흐름이 여러 서비스를 거칠 때 전체 경로 시각화할 수 있다.
- 개발자 친화적인 사용성
- 단순히 의존성 추가만으로 기본적인 기능을 사용할 수 있다.
단점
- Sleuth 단독으로는 시각화를 할 수 없다.
- 그래서 Zipkin이나 OpenTelemetry UI를 연동해야 한다.
- 비동기/스레드 풀 연계 시 문제가 생길 수 있다.
@Async,CompletableFuture,Executor사용 시 Trace가 전파되지 않는다.- 이를 위해
LazyTraceExecutor,TraceRunnable등 별도의 처리가 필요하다.
- 성능 오버헤드
- 추적 데이터 생성, 전파, 전송 등의 작업으로 인해 소폭의 성능 저하가 발생할 수 있다.
- 복잡한 환경에서는 세부적인 튜닝이 필요하다.
- 예시
- 메시지 큐 사용
- 비표준 HTTP 클라이언트 사용 시
- 예시
Micrometer Tracing
정의
- Spring Boot 3.X 환경에서 분산 추적 기능을 제공하는 라이브러리
- 기존의 Spring Cloud Sleuth를 대체하는 라이브러리다.
- Micrometer Metrics + Tracing + Logging을 통합한 구조다.
- OpenTelemetry, Brave, Zipkin, Jaeger 등 다양한 백엔드와 연동 가능하다.
- 일종의
현대적인 Sleuth + Metrics 통합판이다.
특징
- 표준 기반
- OpenTelemetry, Brave 등 다양한 구현체를 지원한다.
- 통합 관측성
- Metrics, Logs, Traces를 하나로 통합하였다.
- Micrometer 기반
- Sleuth 대체
- Spring Boot 3.X에서는 Sleuth가 deprecated되었다.
- 쉬운 백엔드 연동
- Zipkin, Jaeger, Honeycomb, Datadog 등 다양한 APM을 연동할 수 있다.
- 최소한의 설정
- Spring Boot와 자동 구성 (Auto Configuration)을 지원한다.
장점
- Sleuth보다 구조가 단순하고 경량화되었다.
- 모듈화가 잘 되어 있어 필요한 기능만 선택적으로 사용할 수 있다.
- 기존 Sleuth보다 더 가볍고 유연한 설계
- OpenTelemetry와의 높은 호환성
- OpenTelemetry 사용 시 표준 방식으로 trace 데이터를 전송할 수 있다.
- 다양한 백엔드(APM) 연동이 훨씬 쉽다.
- Micrometer Metrics와의 완벽한 통합
- 트레이싱 외에도 메트릭 수집과 함께 관측성을 통합할 수 있다.
- Metrics, Trace, Log를 같은 컨텍스트로 관리할 수 있다.
- Spring Boot 3 공식 지원
- 최신 Spring 관측성 철학(Spring Observability)에 맞춰 공식적으로 도입되었다.
- Sleuth는 더 이상 유지보수되지 않는다.
단점
- 초기 전환 시 학습이 필요하다.
- Sleuth에 익숙했던 개발자에겐 새로운 방식이 다소 생소할 수 있다.
- 개념과 설정 방식이 다르다.
- 예시 : Brave vs OpenTelemetry
- Spring Boot 2.X에서는 호환이 어렵다.
- Micrometer Tracing은 Spring Boot 3부터 본격적으로 도입되었다.
- 그러다보니 하위 버전의 스프링 부트에 호환성이 부족하다.
- 초기 설정이 간단하지만, 커스터마이징은 복잡하다.
- 커스텀 Sampler, Exporter 구성은 Sleuth보다 설정 항목이 많을 수 있다.
Zipkin + Micrometer Tracing 연동
사용하는 스프링 부트의 버전에 따라
스프링 부트 애플리케이션과 Zipkin을 연동할
라이브러리를 선택하자.
나는 스프링 3.X 버전을 사용하기 때문에
Micrometer Tracing를 사용할 것이다.
build.gradle
Micrometer Tracing을 사용하기 위해 build.gradle에 아래와 같이 의존성을 추가하자.
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation "io.micrometer:micrometer-tracing-bridge-brave"
implementation "io.zipkin.reporter2:zipkin-reporter-brave"환경설정
환경설정 파일을 수정해주자.
management:
tracing:
sampling:
probability: 1.0
propagation:
consume: B3
produce: B3
enabled: true
zipkin:
tracing:
endpoint: http://localhost:9411/api/v2/spans
logging:
pattern:
correlation: '%5p [${spring.application.name:},%X{traceId:-},%X{spanId:-}]'위와 같이 설정하게 되면 로그에 애플리케이션명, Trace ID, Span ID가 출력된다.
그러면 로그가 (생략) [user-service,68025e8849df8dfac05333ca74aff383,4dc4bafb37b7eead] (생략)와 같이 나온다.
확인해보기
우선 기존과 동일하게 주문 서비스의 인스턴스가 내려가 있는 상태로
사용자 서비스를 호출해본다.
그 다음에 Zipkin 페이지를 들어가보자.
맨 처음에 들어가면 아무 것도 나오지 않는다. 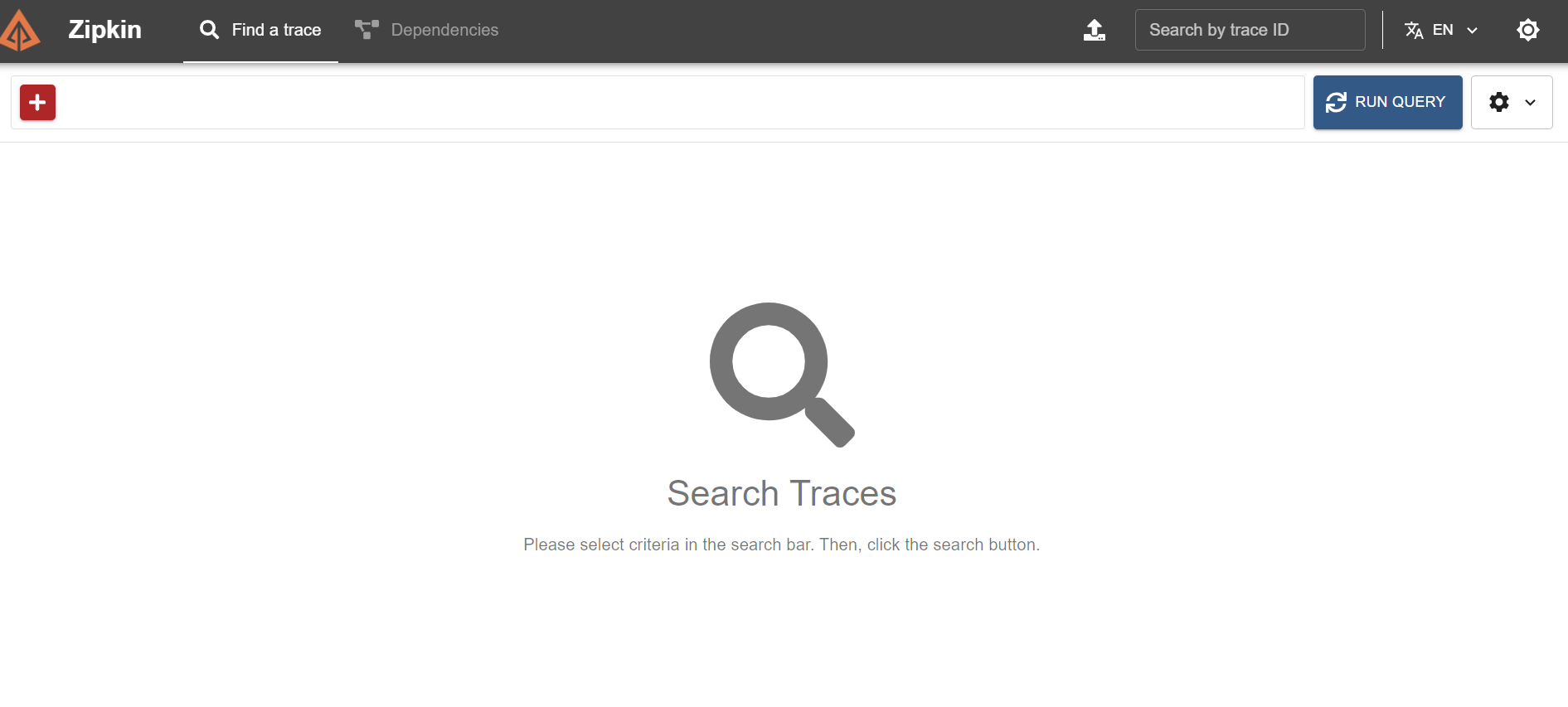
이번엔 우측에 있는 RUN QUERY 버튼을 눌러보자. 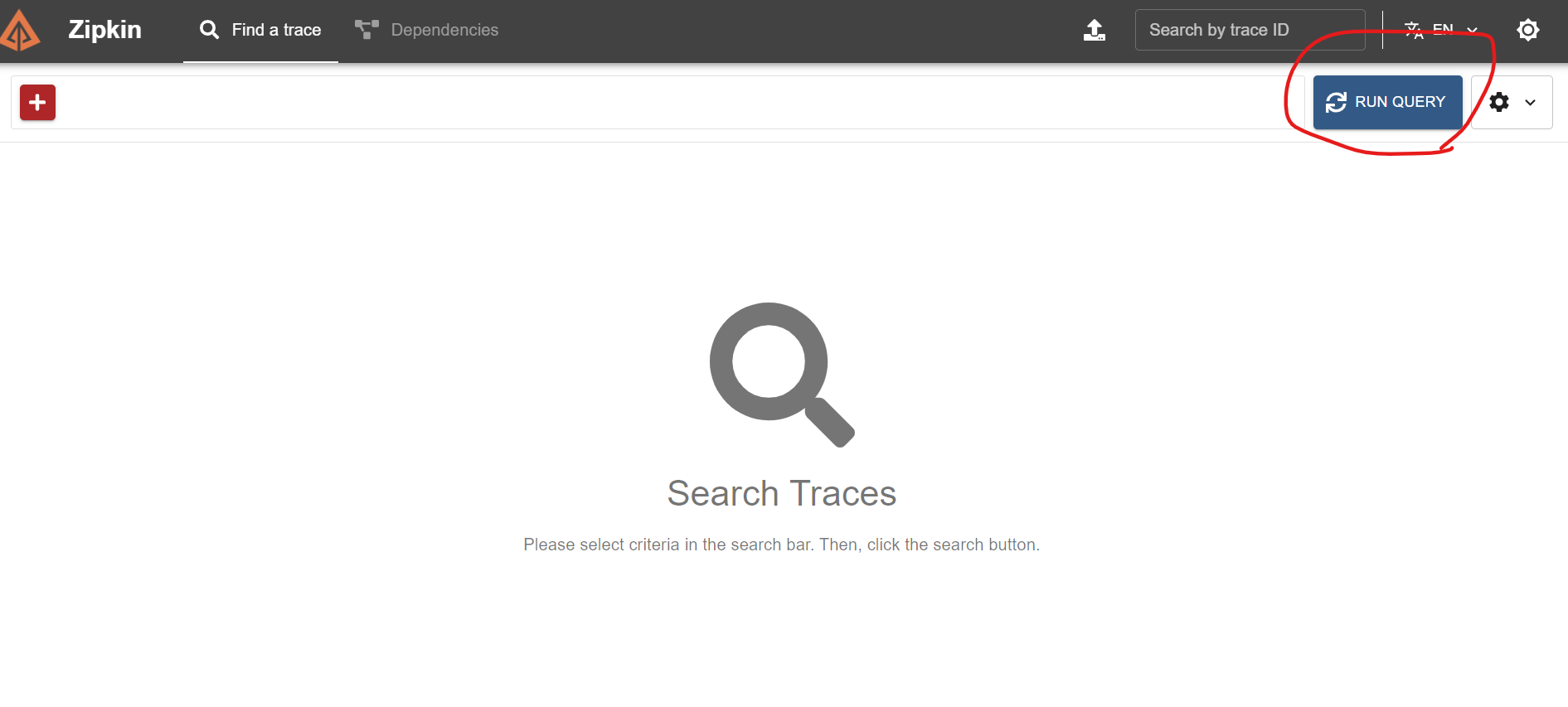
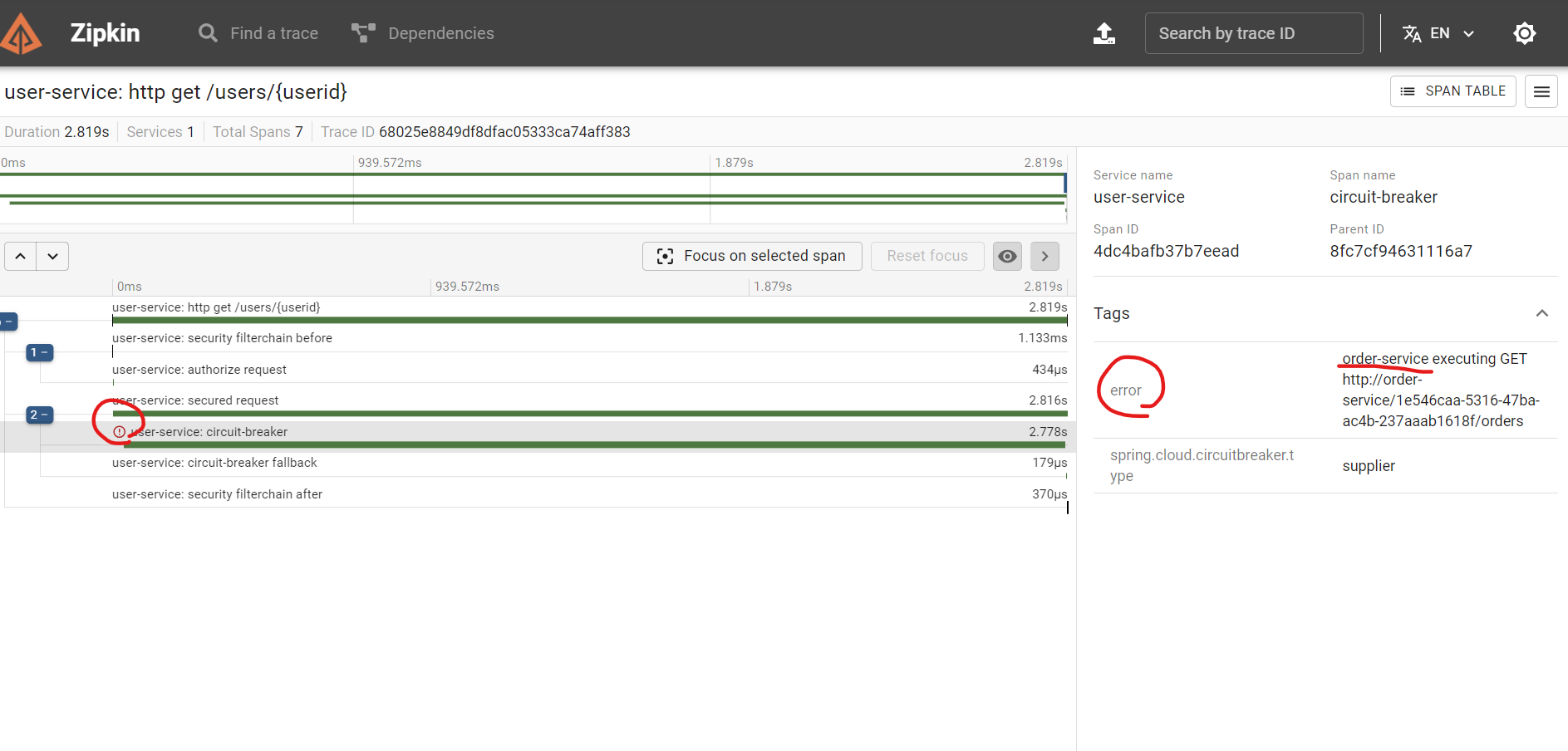
그러면 이렇게 문제가 발생한 경우에는 아이콘과 함께 강조 표시가 있는 것을 알 수 있다. 
이번엔 우측의 SHOW 버튼을 눌러서 상세 페이지에 들어가보자. 
그러면 각 Trace와 Span에 대한 정보가 간략하게 나와있는 것을 알 수 있다. 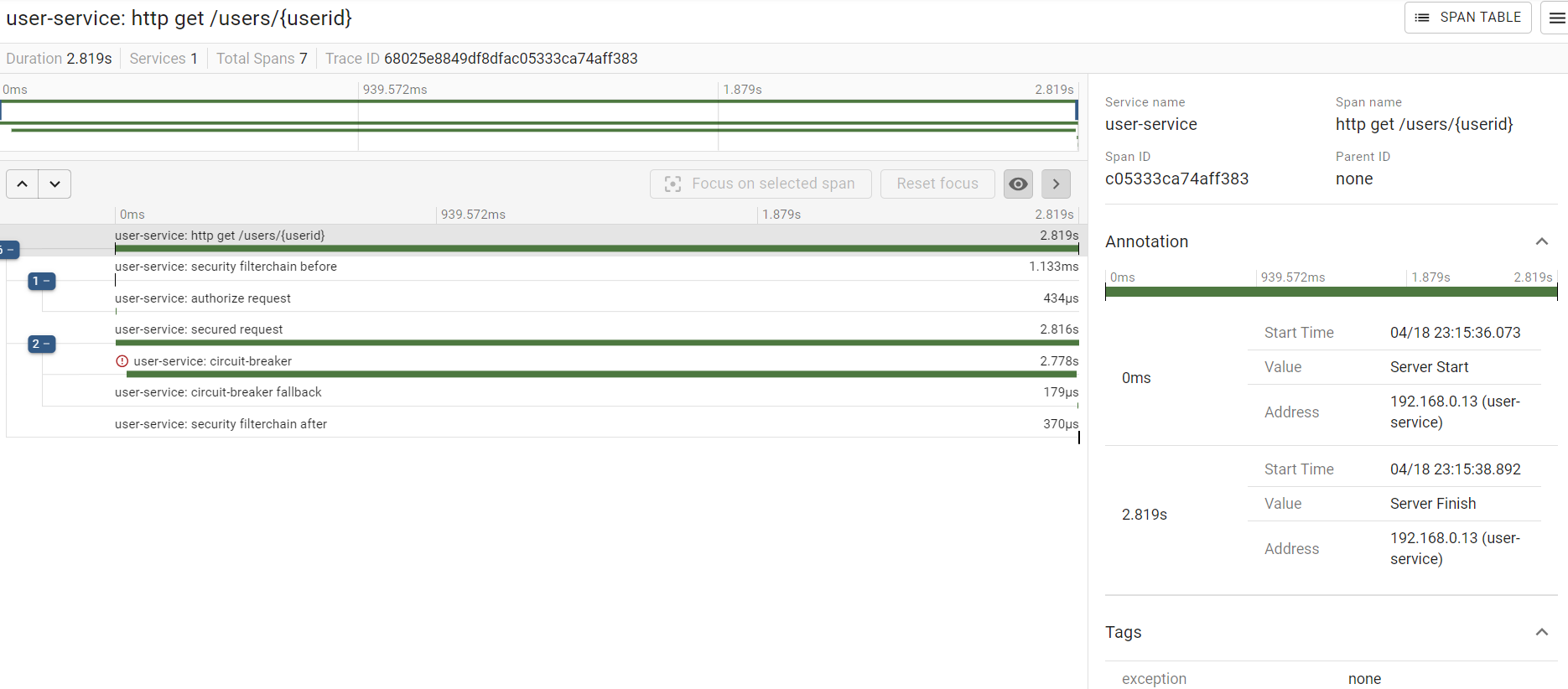
여기서 에러 아이콘이 있는 부분을 눌러보면 상세한 내용을 확인할 수 있다.
우측의 정보 상세 정보 영역을 통해서 어느 부분에서 문제가 발생했는지 파악할 수 있다.